
Tasklets — Lightweight threads¶
Tasklets wrap functions, allowing them to be launched as microthreads to be run within the scheduler.
Launching a tasklet:
stackless.tasklet(callable)(*args, **kwargs)
That is the most common way of launching a tasklet. This does not just create a tasklet, but it also automatically inserts the created tasklet into the scheduler.
Example - launching a more concrete tasklet:
>>> def func(*args, **kwargs):
... print("scheduled with", args, "and", kwargs)
...
>>> stackless.tasklet(func)(1, 2, 3, string="test")
<stackless.tasklet object at 0x01C58030>
>>> stackless.run()
scheduled with (1, 2, 3) and {'string': 'test'}
Tasklets, main, current and more¶
There are two especially notable tasklets, the main tasklet and the current tasklet.
The main tasklet is fixed, and it is the initial thread of execution of your application. Chances are that it is running the scheduler.
The current tasklet however, is the tasklet that is currently running. It might be the main tasklet, if no other tasklets are being run. Otherwise, it is the entry in the scheduler’s chain of runnable tasklets, that is currently executing.
Example - is the main tasklet the current tasklet:
stackless.main == stackless.current
Example - is the current tasklet the main tasklet:
stackless.current.is_main == 1
Example - how many tasklets are scheduled:
stackless.runcount
Note
The main tasklet factors into the stackless.runcount value. If you
are checking how many tasklets are in the scheduler from your main loop,
you need to keep in mind that there will be another tasklet in there over
and above the ones you explicitly created.
The tasklet class¶
-
class
tasklet(func=None, args=None, kwargs=None)¶ This class exposes the form of lightweight thread (the tasklet) provided by Stackless-Python. Wrapping a callable object and arguments to pass into it when it is invoked, the callable is run within the tasklet.
Tasklets are usually created in the following manner:
>>> stackless.tasklet(func)(1, 2, 3, name="test")
The above code is equivalent to:
>>> t = stackless.tasklet() >>> t.bind(func) >>> t.setup(1, 2, 3, name="test")
and
>>> t = stackless.tasklet() >>> t.bind(func, (1, 2, 3), {"name":"test"}) >>> t.insert()
Note that when an implicit
tasklet.insert()is invoked, there is no need to hold a reference to the created tasklet.
-
tasklet.__init__(func=None, args=None, kwargs=None)¶ Just calls
tasklet.bind(func, args, kwargs) and returnsNone
-
tasklet.bind(func=None, args=None, kwargs=None)¶ Bind the tasklet to the given callable object, func:
>>> t = stackless.tasklet() >>> t.bind(func)
In most every case, programmers will instead pass func into the tasklet constructor:
>>> t = stackless.tasklet(func)
Note that the tasklet cannot be run until it has been provided with arguments to call func. They can be provided as args and/or kwargs to this function, or through a subsequent call to
tasklet.setup(). The difference is that when providing them totasklet.bind(), the tasklet is not made runnable yet.New in version 3.7.6: If func is not
None, this method also sets theContextobject of this tasklet to theContextobject of the current tasklet. Therefore it is usually not required to set the context explicitly.func can be
Nonewhen providing arguments, in which case a previous call totasklet.bind()must have provided the function.To clear the binding of a tasklet set all arguments to
None. This is especially useful, if you run a tasklet only partially:>>> def func(): ... try: ... ... # part 1 ... stackless.schedule_remove() ... ... # part 2 ... finally: ... ... # cleanup >>> t = stackless.tasklet(func)() >>> stackless.enable_softswitch(True) >>> stackless.run() # execute part 1 of func >>> t.bind(None) # unbind func(). Don't execute the finally block
If a tasklet is alive, it can be rebound only if the tasklet is not the current tasklet and if the tasklet is not scheduled and if the tasklet is restorable.
bind()raisesRuntimeError, if these conditions are not met.
-
tasklet.setup(*args, **kwargs)¶ -
tasklet.__call__(*args, **kwargs)¶ Provide the tasklet with arguments to pass into its bound callable:
>>> t = stackless.tasklet() >>> t.bind(func) >>> t.setup(1, 2, name="test")
In most every case, programmers will instead pass the arguments and callable into the tasklet constructor instead:
>>> t = stackless.tasklet(func)(1, 2, name="test")
Note that when tasklets have been bound to a callable object and provided with arguments to pass to it, they are implicitly scheduled and will be run in turn when the scheduler is next run.
The method
setup()is equivalent to:>>> def setup(self, *args, **kwargs): >>> assert isinstance(self, stackless.tasklet) >>> with stackless.atomic(): >>> if self.alive: >>> raise(RuntimeError("tasklet is alive") >>> self.bind(None, args, kwargs) >>> self.insert() >>> return self
-
tasklet.insert()¶ Insert a tasklet at the end of the scheduler runnables queue, given that it isn’t blocked. Blocked tasklets need to be reactivated by channels.
-
tasklet.remove()¶ Remove a tasklet from the runnables queue.
Note
If this tasklet has a non-trivial C-state attached, Stackless will kill the tasklet when the containing thread terminates. Since this will happen in some unpredictable order, it may cause unwanted side-effects. Therefore it is recommended to either run tasklets to the end or to explicitly
kill()them.
-
tasklet.run()¶ If the tasklet is alive and not blocked on a channel, then it will be run immediately. However, this behaves differently depending on whether the tasklet is in the scheduler’s chain of runnable tasklets.
Example - running a tasklet that is scheduled:
>>> def f(name): ... while True: ... c=stackless.current ... m=stackless.main ... assert c.scheduled ... print("%s id=%s, next.id=%s, main.id=%s, main.scheduled=%r" % (name,id(c), id(c.next), id(m), m.scheduled)) ... stackless.schedule() ... >>> t1 = stackless.tasklet(f)("t1") >>> t2 = stackless.tasklet(f)("t2") >>> t3 = stackless.tasklet(f)("t3") >>> >>> t1.run() t1 id=36355632, next.id=36355504, main.id=30571120, main.scheduled=True t2 id=36355504, next.id=36355888, main.id=30571120, main.scheduled=True t3 id=36355888, next.id=30571120, main.id=30571120, main.scheduled=True
What you see here is that t1 is not the only tasklet that ran. When t1 yields, the next tasklet in the chain is scheduled and so forth until the tasklet that actually ran t1 - that is the main tasklet - is scheduled and resumes execution.
If you were to run t2 instead of t1, then we would have only seen the output of t2 and t3, because the tasklet calling
runis before t1 in the chain.Removing the tasklet to be run from the scheduler before it is actually run, gives more predictable results as shown in the following example. But keep in mind that the scheduler is still being run and the chain is still involved, the only reason it looks correct is tht the act of removing the tasklet effectively moves it before the tasklet that calls
remove().Example - running a tasklet that is not scheduled:
>>> t2.remove() <stackless.tasklet object at 0x022ABDB0> >>> t2.run() t2 id=36355504, next.id=36356016, main.id=36356016, main.scheduled=True >>> t2.scheduled True
While the ability to run a tasklet directly is useful on occasion, that the scheduler is still involved and that this is merely directing its operation in limited ways, is something you need to be aware of.
-
tasklet.switch()¶ Similar to
tasklet.run()except that the calling tasklet is paused. This function can be used to implement raw scheduling without involving the scheduling queue.The target tasklet must belong to the same thread as the caller.
Example - switch to a tasklet that is scheduled. Function f is defined as in the previous example:
>>> t1 = stackless.tasklet(f)("t1") >>> t2 = stackless.tasklet(f)("t2") >>> t3 = stackless.tasklet(f)("t3") >>> t1.switch() t1 id=36413744, next.id=36413808, main.id=36413680, main.scheduled=False t2 id=36413808, next.id=36413872, main.id=36413680, main.scheduled=False t3 id=36413872, next.id=36413744, main.id=36413680, main.scheduled=False t1 id=36413744, next.id=36413808, main.id=36413680, main.scheduled=False t2 id=36413808, next.id=36413872, main.id=36413680, main.scheduled=False t3 id=36413872, next.id=36413744, main.id=36413680, main.scheduled=False t1 id=36413744, next.id=36413808, main.id=36413680, main.scheduled=False ... Traceback (most recent call last): File "<stdin>", line 1, in <module> File "<stdin>", line 6, in f KeyboardInterrupt >>>
What you see here is that the main tasklet was removed from the scheduler. Therefore the scheduler ran until it got interrupted by a keyboard interrupt.
-
tasklet.raise_exception(exc_class, *args)¶ Raise an exception on the given tasklet. exc_class is required to be a sub-class of
Exception. It is instantiated with the given arguments args and raised within the given tasklet.In order to make best use of this function, you should be familiar with how tasklets and the scheduler deal with exceptions, and the purpose of the TaskletExit exception.
If you try to raise an exception on a tasklet, that is not alive, the method fails, except if exc_class is
TaskletExitand the tasklet already ended.Changed in version 3.3.7: In case of an error Stackless versions before 3.3.7 raise
exc_class(*args). Later versions raisesRuntimeError.
-
tasklet.throw(exc=None, val=None, tb=None, pending=False)¶ Raise an exception on the given tasklet. The semantics are similar to the raise keywords, and so, this can be used to send an existing exception to the tasklet.
if pending evaluates to True, then the target tasklet will be made runnable and the caller continues. Otherwise, the target will be inserted before the current tasklet in the queue and switched to immediately.
If you try to raise an exception on a tasklet, that is not alive, the method raises
RuntimeErroron the caller. There is one exception: you can safely raiseTaskletExit, if the tasklet already ended.
-
tasklet.kill(pending=False)¶ Terminates the tasklet and unblocks it, if the tasklet was blocked on a channel. If the tasklet already ran to its end, the method does nothing. If the tasklet has no thread, the method simply ends the tasklet. Otherwise it raises the TaskletExit exception on the tasklet. pending has the same meaning as for
tasklet.throw().This can be considered to be shorthand for:
>>> if t.alive: >>> t.throw(TaskletExit, pending=pending)
-
tasklet.set_atomic(flag)¶ This method is used to construct a block of code within which the tasklet will not be auto-scheduled when preemptive scheduling. It is useful for wrapping critical sections that should not be interrupted:
old_value = t.set_atomic(1) # Implement unsafe logic here. t.set_atomic(old_value)
Note that this will also prevent involuntary thread switching, i.e. the thread will hang on to the GIL for the duration.
-
tasklet.bind_thread([thread_id])¶ Rebind the tasklet to the current thread, or a Python® thread with the given thread_id.
This is only safe to do with just-created tasklets, or soft-switchable tasklets. This is the case when a tasklet has just been unpickled. Then it can be useful in order to hand it off to a different thread for execution.
The relationship between tasklets and threads is covered elsewhere.
-
tasklet.set_ignore_nesting(flag)¶ It is probably best not to use this until you understand nesting levels:
old_value = t.set_ignore_nesting(1) # Implement unsafe logic here. t.set_ignore_nesting(old_value)
-
tasklet.set_context(context)¶ New in version 3.7.6.
Set the
Contextobject to be used while this tasklet runs.Every tasklet has a private context attribute. When the tasklet runs, this context becomes the current context of the thread.
Parameters: context (
contextvars.Context) – the context to be setReturns: the tasklet itself
Return type: Raises: - RuntimeError – if the tasklet is bound to a foreign thread and is current or scheduled.
- RuntimeError – if called from within
contextvars.Context.run().
Note
The methods
__init__(),bind()and__setstate__()also set the context of the tasklet they are called on to the context of the current tasklet. Therefore it is usually not required to set the context explicitly.Note
This method has been added on a provisional basis (see PEP 411 for details.)
-
tasklet.context_run(callable, *args, **kwargs)¶ New in version 3.7.6.
Execute
callable(*args, **kwargs)in the context object of the tasklet the contest_run method is called on. Return the result of the execution or propagate an exception if one occurred. This method is roughly equivalent following pseudo code:def context_run(self, callable, *args, **kwargs): saved_context = stackless.current._internal_get_context() stackless.current.set_context(self._internal_get_context()) try: return callable(*args, **kw) finally: stackless.current.set_context(saved_context)
See also
contextvars.Context.run()for additional information. Use this method with care, because it lets you manipulate the context of another tasklet. Often it is sufficient to use a copy of the context instead of the original object:copied_context = tasklet.context_run(contextvars.copy_context) copied_context.run(...)
Note
This method has been added on a provisional basis (see PEP 411 for details.)
-
tasklet.__del__()¶ New in version 3.7.
Finalize the tasklet. This is a PEP 442 finalizer. If this tasklet is alive and has a non-trivial C-state attached, the finalizer repeatedly kills the tasklet for upmost 10 times until it is dead. Then, if this tasklet still has non-trivial C-state attached, the finalizer appends the tasklet to
gc.garbage. This is done, because releasing the C-state could cause undefined behavior.You should not call this method from Python®-code.
-
tasklet.__reduce_ex__(protocol)¶
-
tasklet.__setstate__(state)¶ -
New in version 3.7.6: If the tasklet becomes alive through this call and if state does not contain a
Contextobject, then__setstate__()also sets theContextobject of the tasklet to theContextobject of the current tasklet.Parameters: state ( tuple) – the state as given by__reduce_ex__(...)[2]Returns: self Return type: taskletRaises: RuntimeError – if the tasklet is already alive
The following (read-only) attributes allow tasklet state to be checked:
-
tasklet.alive¶ This attribute is
Truewhile a tasklet is still running. Tasklets that are not running will most likely have either run to completion and exited, or will have unexpectedly exited through an exception of some kind.
-
tasklet.paused¶ This attribute is
Truewhen a tasklet is alive, but not scheduled or blocked on a channel. This state is entered after atasklet.bind()with 2 or 3 arguments, atasklet.remove()or by the main tasklet, when it is acting as a watchdog.
-
tasklet.blocked¶ This attribute is
Truewhen a tasklet is blocked on a channel.
-
tasklet.scheduled¶ This attribute is
Truewhen the tasklet is either in the runnables list or blocked on a channel.
-
tasklet.restorable¶ This attribute is
True, if the tasklet can be completely restored by pickling/unpickling. If a tasklet is restorable, it is possible to continue running the unpickled tasklet from whatever point in execution it may be.All tasklets can be pickled for debugging/inspection purposes, but an unpickled tasklet might have lost runtime information (C stack). For the tasklet to be runnable, it must not have lost runtime information (C stack usage for instance).
The following attributes allow checking of user set situations:
-
tasklet.atomic¶ This attribute is
Truewhile this tasklet is within atasklet.set_atomic()block
-
tasklet.block_trap¶ Setting this attribute to
Trueprevents the tasklet from being blocked on a channel.
-
tasklet.ignore_nesting¶ This attribute is
Truewhile this tasklet is within atasklet.set_ignore_nesting()block
-
tasklet.context_id¶ New in version 3.7.6.
This attribute is the
id()of theContextobject to be used while this tasklet runs. It is intended mostly for debugging.Note
This attribute has been added on a provisional basis (see PEP 411 for details.)
The following attributes allow identification of tasklet place:
-
tasklet.is_current¶ This attribute is
Trueif the tasklet is the current tasklet of the thread it belongs to. To see if a tasklet is the currently executing tasklet in the current thread use the following Python® code:import stackless def is_current(tasklet): return tasklet is stackless.current
-
tasklet.is_main¶ This attribute is
Trueif the tasklet is the main tasklet of the thread it belongs to. To check if a tasklet is the main tasklet of the current thread use the following Python® code:import stackless def is_current_main(tasklet): return tasklet is stackless.main
-
tasklet.thread_id¶ This attribute is the id of the thread the tasklet belongs to. If its thread has terminated, the attribute value is
-1.The relationship between tasklets and threads is covered elsewhere.
In almost every case, tasklets will be linked into a chain of tasklets. This might be the scheduler itself, otherwise it will be a channel the tasklet is blocked on.
The following attributes allow a tasklets place in a chain to be identified:
-
tasklet.prev¶ The previous tasklet in the chain that this tasklet is linked into.
-
tasklet.next¶ The next tasklet in the chain that this tasklet is linked into.
The following attributes are intended only for implementing debuggers, profilers, coverage tools and the like. Their behavior is part of the implementation platform, rather than part of the language definition, and thus may not be available in all Stackless-Python implementations.
-
tasklet.trace_function¶
-
tasklet.profile_function¶ The trace / profile function of the tasklet. These attributes are the tasklet counterparts of the functions
sys.settrace(),sys.gettrace(),sys.setprofile()andsys.getprofile().
Tasklet Life Cycle¶
Here is a somewhat simplified state chart that shows the life cycle of a tasklet instance. The chart does not show the nesting-level, the thread-id and the flags atomic, ignore-nesting, block-trap and restorable.
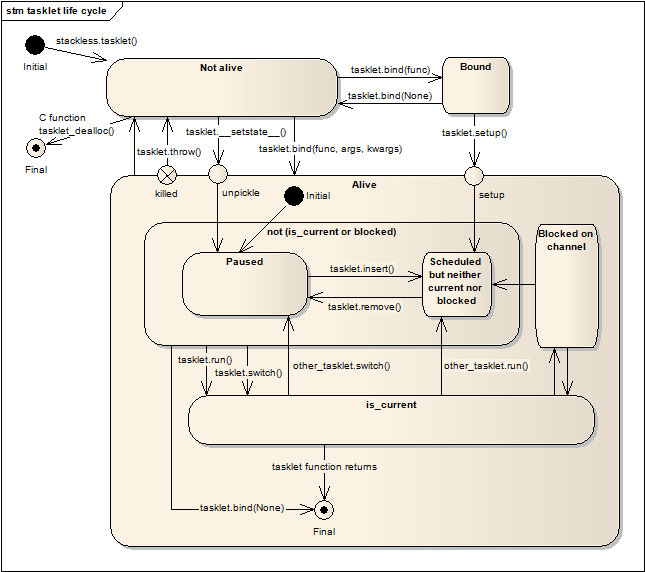
Furthermore the diagram does not show the scheduler functions
stackless.run(), stackless.schedule() and
stackless.schedule_remove(). For the purpose of understanding the
state transitions these functions are roughly equivalent to the following
Python® definitions:
def run():
main = stackless.current
def watchdog():
while stackless.runcount > 1:
stackless.current.next.run()
main.switch()
stackless.tasklet(watchdog)().switch()
def schedule():
stackless.current.next.run()
def schedule_remove():
stackless.current.next.switch()
Tasklets and Context Variables¶
New in version 3.7.6.
Version 3.7 of the Python® programming language adds context variables, see module contextvars.
Usually they are used in connection with
asyncio, but they are a useful concept for Stackless-Python too.
Using context variables and multiple tasklets together didn’t work well in Stackless-Python versions 3.7.0 to
3.7.5, because all tasklets of a given thread shared the same context.
Starting with version 3.7.6 Stackless-Python adds explicit support for context variables. Design requirements were:
- Be fully compatible with standard Python® and its design decisions.
- Be fully compatible with previous applications of Stackless-Python, which are unaware of context variables.
- Automatically share a context between related tasklets. This way a tasklet, that needs to set a context variable, can delegate this duty to a sub-tasklet without the need to manage the context of the sub-tasklet manually.
- Enable the integration of tasklet-based co-routines into the
asyncioframework. This is an obvious application which involves context variables and tasklets. See slp-coroutine for an example.
Now each tasklet object has it own private context attribute. The design goals have some consequences:
- The active
Contextobject of a thread (as defined by the Python® programming language) is the context of thecurrenttasklet. This implies that a tasklet switch, switches the active context of the thread. - In accordance with the design decisions made in PEP 567 the context of a tasklet can’t be
accessed directly [1], but you can use the method
tasklet.context_run()to run arbitrary code in this context. For instancetasklet.context_run(contextvars.copy_context())returns a copy of the context. The attributetasklet.context_idcan be used to test, if two tasklets share the context. - If you use the C-API, the context attribute of a tasklet is stored in the field context of the structure
PyTaskletObjectorPyThreadState. This field is is either undefined (NULL) or a pointer to aContextobject. A tasklet, whose context isNULLmust behave identically to a tasklet, whose context is an emptyContextobject [2]. Therefore the Python® API provides no way to distinguish both states. Whenever the context of a tasklet is to be shared with another tasklet and tasklet->context is initially NULL, it must be set to a newly createdContextobject beforehand. This affects the methodscontext_run(),__init__(),bind()and__setstate__()as well as the attributetasklet.context_id. - If the state of a tasklet changes from not alive to bound or to alive (methods
__init__(),bind()or__setstate__()), the context of the tasklet is set to the currently active context. This way a newly initialized tasklet automatically shares the context of its creator. - The
contextvarsimplementation of standard Python® imposes several restrictions on Stackless-Python. Especially the sanity checks inPyContext_Enter()andPyContext_Exit()make it impossible to replace the current context within the execution of the methodcontextvars.Context.run(). In that case Stackless-Python raisesRuntimeError.
Note
Context support has been added on a provisional basis (see PEP 411 for details.)
Footnotes
| [1] | Not exactly true. The return value of tasklet.__reduce_ex__() can contain references to class
contextvars.Context, but it is strongly discouraged, to use them for any other purpose
than pickling. |
| [2] | Setting a context variable to a non default value changes the value of the field context from NULL
to a pointer to a newly created Context object. This can happen anytime in a
library call. Therefore any difference between an undefined context and an empty context causes ill defined
behavior. |